A deep learning approach for electric motor fault diagnosis based on modified InceptionV3
This study presents a new approach to motor fault detection, where InceptionV3 network is integrated with SE channel attention mechanism and SVM classifier to provide improved performance. This section begins by describing the dataset used in this study, followed by a brief introduction to the method of enhancing the data using CLAHE image preprocessing. Subsequently, the InceptionV3 model and SE block are explained, and finally, the process of integrating the SVM into the model is described.
Figure 1 illustrates the methodology and workflow employed in this study.
Figure 1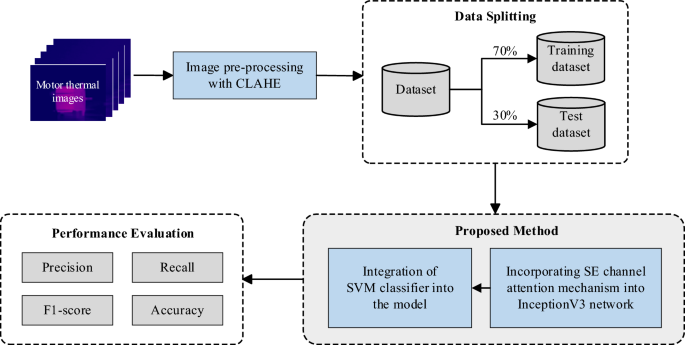
Experiment workflow diagram.
The dataset
This study used an industrial motor dataset created by Najafi et al. from the Electrical and Computer Engineering Laboratory at Babol Noshirvani University of Technology15. The dataset consists of 369 thermal images of three-phase induction motor under 11 types of fault conditions.
The internal structure of the motor used in the creation of the dataset is illustrated in Fig. 2. Different fault conditions in the motor were studied. These include rotor blockage, cooling fan failure and various short-circuit conditions in the stator’s winding.
The images were taken using a Dali-tech T4/T8 infrared thermal imager, and the image resolution is 320 x 240. Although high-resolution images are known to offer superior accuracy in fault detection, practical considerations must also be taken into account. Acquiring high-resolution thermal imaging equipment is often costly, and such images may capture irrelevant features, leading to time and cost inefficiencies.
Therefore, one of our strategies is to enhance low-resolution images through technique such as image preprocessing and leveraging the model’s feature extraction capabilities.
Figure 2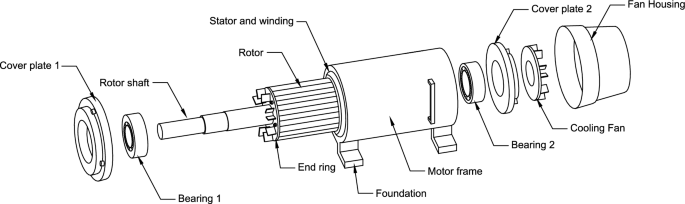
Structure of an induction motor.
Table 1 shows the categories of motor faults and a sample image from each category in the dataset. The labels “A”, “B” and “C” in the table represent the three phases of the induction motor, while SCT refers to the number of Short-Circuited Turns within the motor. The value of SCT is expressed as a percentage in this representation.
The thermal images were captured from the motor operating under various conditions. These include short circuit in one phase with SCT of 10%, 30%, and 50%; short circuit in two phases with SCT of 10%, 30%, and 50%; short circuit in three phases with SCT of 10% and 30%; no-load; cooling fan failure; and rotor failure. It can be observed that as the number of faulty motor phases or the percentage of SCT increases, the thermal variation of the motor becomes more pronounced.
Table 1 The categories of motor’s faults in the dataset.Full size table[3]
Based on the visual analysis, it is evident that the thermal variation in infrared images of motor under different fault conditions can provide crucial information for successful fault classification.
However, it is also observed that for certain fault categories, there are significant similarities among the images. Additionally, the inclusion of rotor fault, fan fault, and no-load categories further complicates the differentiation of these fault types from the SCT faults. Therefore, the classification model must possess advanced feature extraction capabilities and a robust classification mechanism to effectively address this challenge.
Considering these factors, we have selected the InceptionV3 model, not only because of its high accuracy in image classification but also because it has powerful feature extraction capabilities while keeping the model size relatively small. Additionally, we incorporated the SE channel attention mechanism into the model, enabling it to handle deeper features in the images more effectively and further enhancing the model’s recognition accuracy. These qualities will contribute toward effective fault classification.
The details of the proposed method will be elaborated in the subsequent sections.
Image preprocessing using CLAHE
CLAHE is an extension of the traditional Histogram Equalization (HE) technique for image enhancement38.
It is worth noting that the CLAHE technique offers several advantages for infrared thermography. It can enhance the details in infrared thermal images, making subtle temperature changes more visible. Additionally, it significantly increases the contrast of infrared thermal images, making the distinctions between different temperature regions more pronounced.
Moreover, CLAHE can expand the dynamic range of infrared thermal images, resulting in a more uniform representation of temperature values in the image. These aspects contribute to better observation and analysis of heat distribution, as well as avoiding concentration of temperature information within a narrow range. This is particularly useful for detecting and analyzing detailed features such as heat gradients, hotspots, and temperature anomalies.
To apply CLAHE on an image, we adopt a channel-based approach. The image is decomposed into its color components using the Lab color space, where L represents the lightness channel, while a and b represent the chrominance channels. The steps involved in the CLAHE processing are as follows:
- 1.
Convert the input image from RGB to Lab color space.
- 2.
Separate the L, a, and b channels from the Lab image.
- 3.
Apply CLAHE independently to the L channel using a specified block size and contrast limit.
- 4.
Merge the enhanced L channel with the original a and b channels.
- 5.
Convert the image back to RGB color space.
By performing CLAHE exclusively on the L channel, the image’s lightness is selectively enhanced while preserving the original chrominance information.
This approach ensures a balanced enhancement across the image, preserving the color representation. There are two important parameters to be set in the CLAHE algorithm: block size and contrast limit. We referenced the parameters used in the experiments by Farooq et al.39 and, considering our own experimental context, ultimately set the two parameters to 2 x 2 and 0.02 respectively. Figure 3 shows the process of applying CLAHE enhancement to the dataset. Figure 4 illustrates the histogram of the L channel for image labeled “A&B&C30” from Table 1, before and after applying the CLAHE enhancement.
Figure 3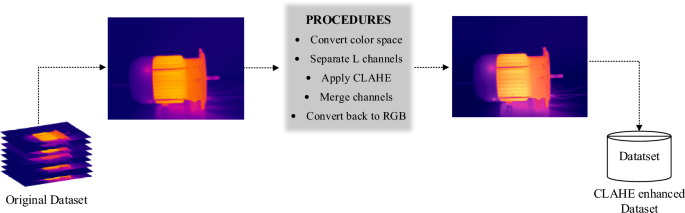
Process of applying CLAHE enhancement to the dataset.
Full size image[4]Figure 4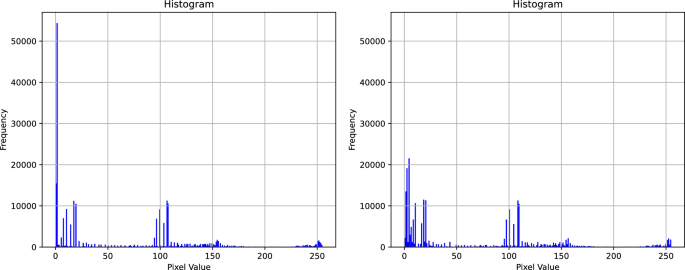
Histogram of the thermal image before and after applying CLAHE enhancement.
Architecture of the InceptionV3 model
The InceptionV3 model, also known as GoogLeNet40, is a widely used deep convolutional neural network architecture. It is renowned for its innovative inception module, which incorporates multiple convolutional filters of different sizes in parallel, allowing the network to capture both local and global features efficiently. This unique structure helps alleviate the vanishing gradient problem41 and enables effective feature extraction at various scales, which is the key advantage of InceptionV3. It utilizes multiple convolutional kernels of different sizes in parallel to process input data, enabling the capture of features across diverse scales.
This enhances the network’s ability to perceive objects and structures of different sizes. Additionally, InceptionV3 incorporates 1 x 1 convolutional layer in the initial module, which not only helps maintain a low parameter count but also provides powerful representational capabilities. In the InceptionV3 network, the convolutional layer is one of its core components.
The convolutional layer extracts feature from input data through convolutional operations and applies weighting and non-linear transformations to these features using convolutional filters and activation functions. The mathematical representation of the convolutional operation can be described using the convolutional operator formula: ££\begin{array}{c}{y}_{i}={\sum }_{i}{x}_{i}*{w}_{ij}+{b}_{i}\end{array}££
(1) where \({x}_{i}\), \({w}_{ij}\), and \({b}_{i}\) represent the input, weights of the convolutional filter, and bias, respectively. In addition to the convolutional operation, the convolutional layer also employs an activation function to perform non-linear transformations on the output feature maps.
ReLU (Rectified Linear Unit) is a commonly used activation function that helps alleviate gradient vanishing issues during training and improves the network’s learning capability. The ReLU function is defined as: ££\begin{array}{c}f\left(x\right)=\left\{\begin{array}{c}0,x0\end{array}\right.\end{array}££
(2) The unique architecture of InceptionV3 combines parallel convolutional filters, dimensionality reduction, and efficient resource management, which contributes to its effectiveness in handling various image datasets and addressing challenges related to computational resources. These features make InceptionV3 a popular choice in computer vision applications, particularly in tasks such as image recognition and object detection.
The InceptionV3 network structure used in this paper is shown in Fig. 5.
Figure 5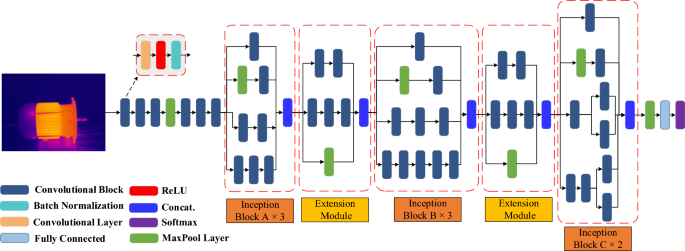
Structures of InceptionV3 network.
The inception block A, B and C are the initial modules of InceptionV3. These modules are constructed using 1 x 1 convolutional branch, 3 x 3 convolutional branch, 7 x 7 convolutional branch, and 1 x 1 convolutional branch with max pooling as shown in Fig. 6. The 1 x 1 convolutional branch is primarily used for dimensionality reduction and feature compression, contributing to a decrease in computational complexity and prevention of overfitting.
The 3 x 3 convolutional branch is employed to capture features at a medium scale, aiding in detecting features such as shapes, edges, and textures. The 7 x 7 convolutional branch, on the other hand, is utilized to capture larger-scale features, facilitating the capturing of the overall structure and contextual information of the features.
Figure 6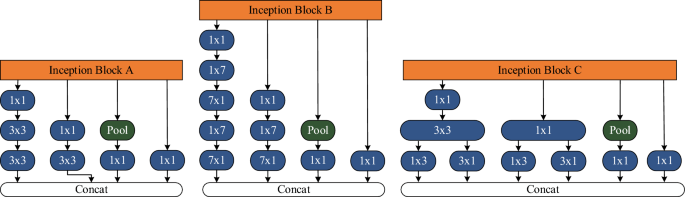
Three different initial modules in InceptionV3.
Integration of SE channel attention mechanism
Squeeze-and-Excitation (SE) is a channel attention mechanism used to enhance the representational power of deep convolutional neural networks. It introduces a lightweight attention module in the network, which dynamically adjusts the importance of each channel in the input feature map through learning.
Compression and excitation are the two key steps of the SE block, where these operations collectively enable the SE attention module to selectively amplify important features while suppressing less relevant ones. The structure of the SE block is shown in Fig. 7.
Figure 7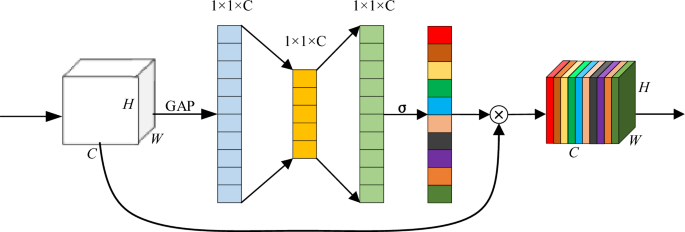
Structure of the SE block.
In the SE channel attention mechanism, several important equations are involved. Firstly, in the Squeeze operation, the input feature map of size H x W x C is compressed to 1 x 1 x C through global average pooling (GAP), where H, W, and C represent the height, width, and number of channels of the original feature map, respectively.
This can be represented as follows: ££\begin{array}{c}{z}_{c}=\frac{1}{H\times W}\sum_{i=1}^{H}\sum_{j=1}^{W}{u}_{c}\left(i,j\right)\end{array}££ (3)
where \({z}_{c}\) represents the Squeeze output of the c-th channel, and uc is the feature value of the c-th channel at position \((i,j)\) in the input feature map. Secondly, in the Excitation stage, the relationships between channels and the generation of channel weights are learned through two fully connected layers and an activation function: ££\begin{array}{c}s=\sigma \left({W}_{2}\delta \left({W}_{1}z\right)\right)\end{array}££
(4) where s represents the generated channel weight vector, \({W}_{1}\) and \({W}_{2}\) are learned weight parameters, z is the output vector from the Squeeze stage, \(\delta\) denotes the ReLU activation function, and \(\sigma\) represents the Sigmoid activation function. Finally, by multiplying the channel weights with the original features, the feature representation after being processed by the SE attention mechanism is obtained:
££\begin{array}{c}y={s}_{c}\cdot {u}_{c}\end{array}££ (5) Through experiments, it has been observed that the SE block can be placed at different positions within the InceptionV3 network, resulting in varying effects.
In the proposed model, the SE block is placed after the Inception module to form the InceptionV3-SE structure. This will facilitate multi-scale feature fusion, enhance feature importance, and reduce computational complexity. In order to integrate the SE block with the InceptionV3, the dimension of the SE block’s input is modified to match the InceptionV3’s output.
Similarly, the number of output channels of the SE block is adjusted to match the number of channels in the subsequent layer of the model. Figure 8 shows the integration of the Inception block and the SE module to form the proposed InceptionV3-SE model.
Figure 8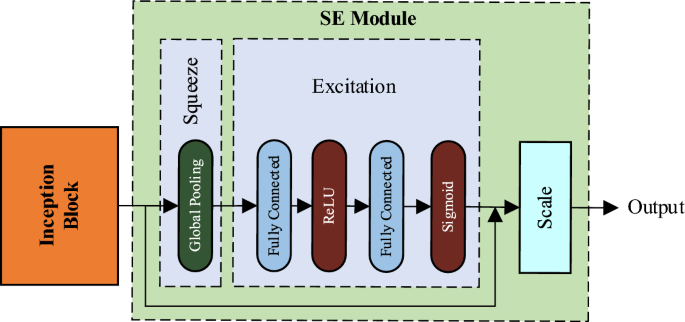
Structure of InceptionV3-SE.
SVM classification
SVM is a powerful supervised learning algorithm that can effectively handle classification problems 42. During the training phase, SVM searches for an optimal hyperplane to separate samples from different classes.
The objective of SVM is to find a decision boundary that maximizes the margin between classes. Furthermore, we chose to use the One-vs-One SVM (OVO-SVM) approach to address the multi-class classification task. Specifically, we trained N(N-1)/2 binary classifiers, where N is the number of classes.
Each binary classifier is used to distinguish between two different classes, and the final predicted class is determined by the number of victories. We utilized a linear kernel function for the SVM. This will simplify the SVM’s computation of feature mapping, resulting in higher efficiency in training and prediction.
The formula for the linear kernel function can be expressed as follows: ££\begin{array}{c}K\left(x,y\right)={x}^{T}y\end{array}££ (6)
where x and y represent the feature vectors of the input samples. In this study, we investigated the effectiveness of using SVM as the main classifier instead of the classification layer in the InceptionV3. The architecture of the proposed InceptionV3-SE-SVM model was designed by replacing the fully connected and SoftMax layers of the InceptionV3-SE model with a linear SVM classifier.
The high-level features extracted by InceptionV3-SE were utilized as inputs to the SVM classifier.
By leveraging the rich features extracted by InceptionV3-SE, it will enhance the classification capability of SVM and improve the accuracy of motor faults classification.
The structure of the InceptionV3-SE-SVM model is depicted in Fig. 9.
Figure 9![]()
Structure of the proposed InceptionV3-SE-SVM model.
References
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size table (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)
- ^ Full size image (www.nature.com)